Визуализация мыслей человека может оказаться реальностью через несколько лет. Группа японских специалистов из лаборатории вычислительной неврологии Международного института передовых телекоммуникационных исследований (ATR Computational Neuroscience Laboratories), расположенного близ Киото, разработала способ преобразования мыслей в визуальную информацию, которую можно отобразить на мониторе компьютера. Об этом сообщает научный журнал Neuron. Суть метода заключается в следующем: когда человек смотрит на какой-либо предмет, свет, отражённый от него, попадает на сетчатку и преобразуется в электрический сигнал, который передаётся по зрительному нерву в соответствующую зону коры головного мозга. Доктору Юкиясу Камитани (Yukiyasu Kamitani) и его коллегам из ATR, совместно с несколькими учёными из ряда других японских институтов и университетов, удалось перехватить этот сигнал и воссоздать на его основе зрительный образ. По словам исследователей, им впервые удалось распознать индивидуальные модели зрительного восприятия людей. Представители ATR заявили, что этот эксперимент стал первым в мире опытом искусственной визуализации зрительного сигнала на основе анализа мозговой активности. Не вводя в мозг какие-либо электроды, экспериментаторы научились достаточно чётко определять — что видел испытуемый человек. Хотя предъявляемые его взору изображения пока ещё чёрно-белые и содержат всего сотню довольно крупных пикселей (применялось изображение Опыт японских учёных открывает дорогу к распознаванию в мозге человека и тех изображений, которые он никогда не видел наяву — снов или воображаемых образов. «Эта технология также может применяться в других сферах, не только в распознавании (в голове) зрительных образов. В будущем она, возможно, сумеет выявлять чувства и сложные эмоциональные состояния», — такую интересную перспективу рисуют Юкиясу Камитани и его коллеги из лаборатории ATR. Технология основана на анализе электрических сигналов, поступающих в головной мозг от сетчатки глаза. Для распознавания в мозге зрительных образов применялась функциональная магнитно-резонансная томография (FMRI). Разумеется, никакой томограф не увидит в голове человека визуальный образ. Все что он может — это показать изменение в кровотоке через определённые зоны коры, связанные с активностью тех или иных групп нейронов. Но, поняв закономерности в таких изменениях, можно научиться выполнять обратное преобразование — от возбуждения нейронов к тому, что вызвало эту реакцию — будь то голоса, мысли или те же самые картинки, стоящие перед глазами. Следует отметить, что этот подход заметно отличается от активно развивающегося параллельного направления «чтения мыслей», в котором применяются специальные шлемы с датчиками электроэнцефалограммы. С одной стороны, применение громоздкого сканера FMRI (в отличие от носимых на голове датчиков мозговых волн) ограничивает опыты по чтению мыслей стенами лабораторий, с другой, оно позволяет гораздо детальнее разглядеть мгновенные изменения в разных зонах коры, вызываемые тем или иным раздражителем.  О «приблизительном угадывании» путём перебора всех вариантов картинок и их сравнения с «мозговым отпечатком» тут не могло быть и речи. Это слишком непродуктивно, ведь даже картинка, состоящая из 100 чёрных или белых квадратов, в пределе даёт 2¹⁰⁰ возможных комбинаций. Это значит, что машина должна была выявлять в картине активности нейронов практически каждый пиксель увиденной человеком картинки по отдельности. Для этого компьютер сначала должен был выявить закономерности в отклике тех или иных нейронов на предъявляемые картинки. Чтобы обучить машину, экспериментаторы показывали испытуемым 440 «стопиксельных» изображений (сгенерированных случайным образом), в течение шесть секунд каждое (с После такого обучения программа нашла корреляцию между пикселями на тестовом изображении и включающимися нейронами. А насколько составленные «правила» оказались верны — было легко проверить.  Ключом к успеху стало построение моделей отклика групп нейронов на разном масштабе для одной и той же картинки. То есть, получив сигнал с томографа, программа разбивала гипотетическое поле Множество таких оценок позволяло машине выставлять цвет уже для каждого пикселя по отдельности, и такое реконструированное изображение оказывалось очень близким к тому, что видел человек на самом деле, хотя, конечно, не совпадало полностью. Детали этой работы можно найти в статье журнала Neuron. 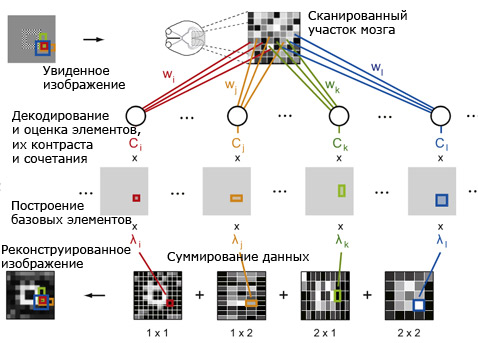 Хотя новая технология пока находится в зачаточном состоянии, до сих пор воспроизведение «мозговых образов» было возможно только в научно-фантастических произведениях, так что впору говорить о серьёзном достижении. Сегодня учёные способны получать только простейшие картинки, но они уверены, что усовершенствованная технология позволит в подробностях узнавать, о чём человек думает. 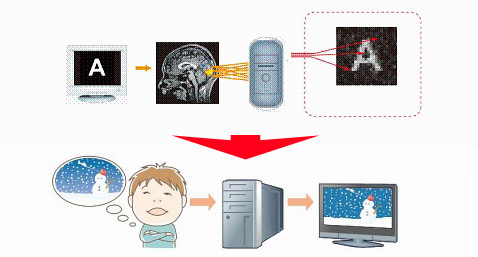 Впрочем, чтобы существенно повысить разрешение таких распознаваемых образов, а заодно — научиться считывать и информацию о цвете пикселей, потребуется ещё несколько лет экспериментов. Однако доктор Кан Чэн (Kang Cheng) из японского института исследования мозга (RIKEN Brain Science Institute) предсказывает, что дальнейшее развитие этой технологии в течение 10 лет не только позволит добавить к картинкам цвет, но вообще — перейти к буквальному чтению мыслей «с некоторой степенью точности». | |