Две группы американских и британских исследователей, изучающие феномены изменения языков во времени, пришли к выводу о существовании своего рода естественного отбора в эволюции языков. Применив к анализу индоевропейских языков методики, разработанные для изучения эволюции видов, биологи подтвердили хорошо известную лингвистам закономерность, что слова в языке изменяются тем быстрее, чем реже они используются. Аналогичная закономерность справедлива и для биологической эволюции: наименее важные для организма морфологические признаки и участки генома обычно подвержены самым быстрым эволюционным изменениям. Впервые на параллели между эволюцией биологических видов и человеческих языков указал Чарльз Дарвин в книге «Происхождение человека». Сегодня это мнение подтверждается строгими статистическими методами. В журнале Nature опубликованы сразу две статьи, посвящённые изучению темпов лингвистической эволюции в зависимости от частоты словоупотребления:
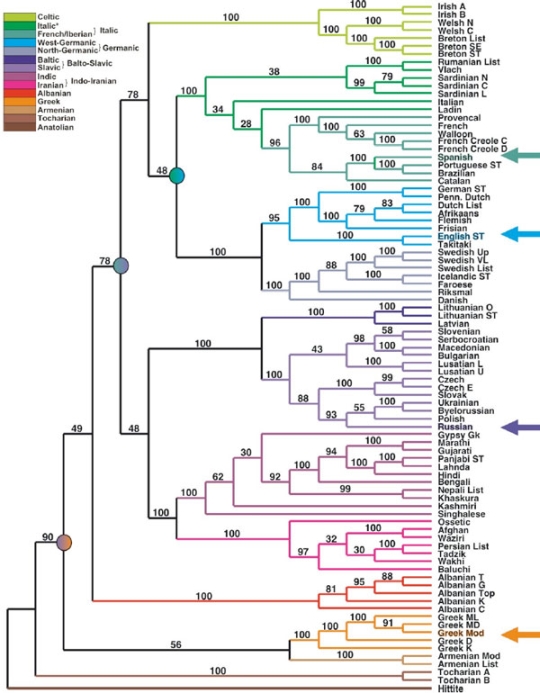
Ведущие авторы обеих статей — биологи. С результатами обоих исследований можно ознакомиться в последнем выпуске журнала.  Первое исследованиеВ первой статье, написанной американскими эволюционистами-теоретиками и математиками, показано, что скорость «превращения» английских неправильных глаголов в правильные зависит от частоты использования конкретного глагола. В древнеанглийском языке, бывшем в употреблении около 800 годов новой эры (так называемый язык «Беовульфа»), существовало несколько классов глаголов, различающихся по способу образования прошедшего времени. В течение последующих 1200 лет шёл процесс «регуляризации»: все эти классы постепенно «пожирались» самым распространённым, в котором прошедшее время и причастие прошедшего времени образуется путём прибавления к глаголу суффикса -(e)d. В современном английском все прочие классы сохранились лишь в виде рудиментов — так называемых «неправильных» глаголов. Класс правильных глаголов является единственным продуктивным, то есть все новые глаголы, появляющиеся в английском языке, автоматические попадают в него и спрягаются по аналогии с другими правильными глаголами (так, «молодой» глагол to Google со значением «пользоваться поисковой системой Google» имеет форму прошедшего времени и причастия Googled). Эксперты из Гарвардского университета в США изучили историческую судьбу 177 глаголов, которые имелись в древнеанглийском (и все были неправильными) и сохранились поныне. В среднеанглийском (язык «Кентерберийских рассказов» Чосера, бывший в употреблении в Авторы разделили глаголы на 6 классов по частоте их встречаемости в современных английских текстах. С этой целью был проанализирован большой корпус текстов CELEX, включающий в общей сложности 17,9 млн английских слов. В первый класс попали два наиболее часто используемых глагола (be «быть», have «иметь»); оба по сей день остаются неправильными. Во втором классе оказалось 11 глаголов, и все они сегодня тоже неправильные. Из 37 глаголов третьего класса всё оставались неправильными в среднеанглийском, но 4 стали правильными в современном английском (help «помогать», reach «достигать», walk «ходить», work «работать»). В четвёртом классе из 65 глаголов были неправильными в среднеанглийском 57, в современном — 37. Соответствующие цифры для пятого класса — 50, 29, 14; для шестого — 12, 9, 1. Анализируя эти данные, авторы пришли к заключению, что для глаголов Экстраполируя свои результаты в будущее, авторы предсказывают, что, если выявленные тенденции сохранятся, к 2500 году ещё 15 глаголов из исследованной выборки станут правильными, причём первым скорее всего «регуляризуется» самый редкий из них (to Wed «сочетаться браком»). Строго говоря, он уже отчасти регуляризован: словари разрешают спрягать его также и как правильный глагол (наряду с «неправильной» формой прошедшего времени — Wed, в словарях приводится «правильная» — Wedded). Соавтор исследования Эрез Либерман (Erez Lieberman), аспирант по прикладной математике из Гарвардского университета, говорит: «Будучи часто употребляемым, глагол становится более устойчивым. В языке действует такое же правило естественного отбора, что Второе исследованиеАвторы второго исследования, биологи из Университета Рединга (Великобритания) и Института Главной целью их работы было понять, каким образом все индоевропейские языки произошли от общего для них праязыка, который существовал, по разным подсчётам, от 6 до 10 тыс. лет назад. Авторы стремятся выяснить общие закономерности эволюции языков, её скорость, а также древность расхождения (и, следовательно, степень родства) различных языков. «Наблюдаемый эффект повторяемости слов позволяет нам выделять и идентифицировать сохранившиеся с давних пор лингвистические единицы, то есть слова, которые мы чаще остальных используем в речи», — пояснил профессор эволюционной биологии Марк Пэйджел из Университета Рединга, который руководил сравнительным исследованиям языков. К сожалению, в своей работе авторы не делают попытку сравнить полученные ими результаты с тем, что уже наработано лингвистами. Метод, который используют авторы, фактически является разновидностью глоттохронологии (лексикостатистики), созданной американским лингвистом Моррисом Сводешем в середине XX века. Моррис Сводеш выделил базовый словарь: список из 100 (впоследствии из 200) универсальных понятий, которые важны для всех культур и потому предположительно встречаются во всех языках мира. Лексика (словарный состав) языка всё время меняется, одни слова заменяются другими, но слова, обозначающие понятия из списка Сводеша, обладают особенной устойчивостью. Тем не менее постепенно заменяются они. Сравнивая списки Сводеша для родственных языков и подсчитывая, какое количество понятий обозначается разными словами, можно определить степень родства языков (чем больше совпадений, тем ближе языки). Так, очевидно, что для русского и польского совпадений будет гораздо больше, чем для русского и английского, но меньше, чем для русского и украинского. Если же определить ещё и скорость замены слов из базового списка, то можно с высокой точностью датировать расхождение языков. На практике глоттохронология сталкивается с рядом серьёзных технических и методологических проблем. Например, не всегда очевидно, являются ли два слова родственных языков потомками одного слова, то есть считать ли, что понятие обозначается одинаково или нет. Искажают картину, в частности, слова, заимствованные одним языком у другого, вовсе необязательно родственного (получается, что понятие обозначается одним и тем же словом, но причина на самом деле лежит не в родстве языков, Авторы проанализировали обозначения понятий из Слова из разных языков, обозначающие одно и то же понятие и являющиеся потомками одного и того же слова, объединялись в «родственные группы». Например, слово, выражающее значение «два» во всех индоевропейских языках относится к одной и той же родственной группе (англ. two, нём. zwei, исп. dos, фр. deux, русск. два, и так далее), тогда как, например, значение «хвост» представлено в исследованных 87 языках 28 группами (греч. ουρά, нем. Schwanz, фр. Queue, англ. Tail — примеры слов, относящихся к разным группам). Общее число родственных групп для 200 значений в 87 языках оказалось равным 4049. Для каждого из 200 понятий была определена частота встречаемости. С этой целью авторы проанализировали большой массив данных по устной и письменной речи для четырёх языков: английского, испанского, русского и греческого (от 20 до 100 млн слов для каждого языка). Эти языки представляют далёкие друг от друга ветви индоевропейской семьи. Выяснилось, что частота употребления различных понятий в четырёх языках весьма сходна, иначе говоря, понятия, часто употребляемые в одном из языков, скорее всего Следующим шагом было построение эволюционного древа 87 индоевропейских языков. Основой для построения древа послужила таблица из 87 X 4049 нулей и единиц, отражающая наличие или отсутствие каждой из 4049 словесных групп в каждом из 87 языков. При этом были использованы сложные математические методики построения эволюционных деревьев, разработанные биологами-эволюционистами.
Для «калибровки» древа (определения абсолютной длины ветвей в годах) была использована усреднённая оценка времени начала дивергенции (расхождения) индоевропейских языков — 8700 лет назад (имеющиеся оценки варьируют от 6 до 10 тысяч лет, изменение даты расхождения повлияет на абсолютные длины ветвей древа, но не на их соотношение). На основе построенного древа были вычислены средние скорости замены слов (родственных групп) для каждого из двухсот понятий. Эту скорость можно выразить как «период полураспада» (half-life), то есть как время, в течение которого данное понятие с вероятностью 50% станет обозначаться другим словом (точнее, словом, относящимся к другой родственной группе). Оказалось, что для 200 исследованных понятий это время варьирует от 750 до 10 000 лет. Заметно, что получившееся древо отличается от общепринятого (см. в начале статьи). Интересно, что в новом древе украинский и белорусский ближе к польскому, чем к русскому (русский ответвляется от польско-украино-белорусской группы, которая затем разделяется на три языка), в то время как по традиционным представлениям сначала расходятся западнославянская (включающая польский) и восточнославянская (русский, белорусский, украинский) группы. Причин несовпадений может быть много, результаты построения деревьев во многом зависят от того, как исследователи решают возникающие проблемы (см. выше некоторые примеры). Авторы статьи не описывают подробно лингвистическую часть своей методики, поэтому затруднительно точнее проанализировать причины различия деревьев.  Затем авторы построили графики зависимости скорости словоизменения от частоты словоупотребления в английском, русском, испанском и греческом языках (см. рис). Оказалось, что для каждой части речи в отдельности и для всех понятий в целом между этими двумя показателями наблюдается хорошо выраженная обратная зависимость. Чем чаще употребляется слово, тем медленнее оно изменяется. По мнению исследователей, эта зависимость может объясняться двумя причинами:
Вполне возможно, что работают одновременно оба механизма. Заметно, что они полностью аналогичны ключевым факторам биологической эволюции, а именно скорости мутирования и эффективности стабилизирующего («очищающего») отбора. Авторы предполагают, что «мутации» в наиболее важных словах чаще отсекаются «отбором», потому что такие мутации ведут к наибольшему риску взаимного непонимания. Возможно, именно поэтому из всех частей речи медленнее всего изменяются как раз те, «мутации» в которых почти всегда ведут к полной потере или искажению смысла фразы (числительные, местоимения и «специальные наречия»). Обнаруженная закономерность, скорее всего, справедлива и для других языковых семей. Например, теми же авторами в 2006 году было показано, что понятия, характеризующиеся высокой частотой словоизменения в индоевропейских языках, обладают тем же свойством Авторы отмечают, что найденная закономерность позволяет сделать любопытные прогнозы. В дополнительных материалах к статье также приведена таблица, где перечислены аналогии между лингвистической и биологической эволюцией (ниже представлен её сокращённый перевод):
Сравнение лингвистической эволюции с биологической встречалось ранее во многих работах (например, A. Wedel. Exemplar Models, Evolution and Language Change. // The Linguistic Review. 2006. | |||||||||||||||||||||||||